?向“芯”看齊或可一試">汽車未來(lái)怎么走?向“芯”看齊或可一試
?">半導(dǎo)體產(chǎn)業(yè)霸主:美國(guó)集成電路是怎樣煉成的?
時(shí)隔一年,終于有機(jī)會(huì)再攢一顆芯片
記得兩年前
全球范圍內(nèi),汽車芯片一年銷售額大致是400億刀,其中數(shù)字芯片100億刀:信息娛樂(lè)(中控)芯片約25億刀,均價(jià)在25刀;MCU約60億刀,30億片,均價(jià)2刀;輔助駕駛約17億刀。全球一年大約賣一億輛車,每輛車平均100刀的數(shù)字芯片。其中輔助駕駛芯片處于快速增長(zhǎng)階段。汽車芯片的主要供應(yīng)商,恩智浦,瑞薩數(shù)字部分較多,英飛凌,德州儀器模擬部分較多。汽車芯片是僅存的幾個(gè)利潤(rùn)還不錯(cuò)的市場(chǎng),技術(shù)門檻也并非不可逾越
新一代的中控芯片的架構(gòu)如下圖
虛擬化在硬件上有什么具體要求?這并沒有明確定義
Arm傳統(tǒng)的設(shè)計(jì)是添加足夠大的多級(jí)TLB緩存和table walk緩存
怎么解決這個(gè)問(wèn)題?在Arm服務(wù)器以及下一代手機(jī)芯片參考設(shè)計(jì)中
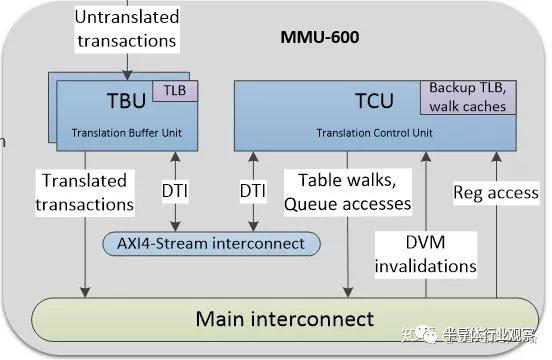
Arm的SMMU600還做了一點(diǎn)改進(jìn),可以把TLB緩存貼近各個(gè)主設(shè)備做布局,在命中的情況下,一個(gè)時(shí)鐘周期就可以完成翻譯;同時(shí),把table walk緩存放到另一個(gè)地方,TLB緩存和table walk緩存通過(guò)內(nèi)部總線互聯(lián)。幾個(gè)主設(shè)備可以同時(shí)使用一個(gè)table walk緩存,減少面積,便于布線的同時(shí),又不失效率。其結(jié)構(gòu)如下圖:
對(duì)于當(dāng)前的汽車芯片,如果沒有系統(tǒng)緩存,那如何減少設(shè)備虛擬化延遲呢?辦法也是有的。汽車的虛擬機(jī)應(yīng)用較為特殊,目前8個(gè)虛擬機(jī)足夠應(yīng)付所有的分屏和多系統(tǒng)需求,并且一旦分配,運(yùn)行階段無(wú)需反復(fù)刪除和生成。我們完全可以利用這點(diǎn),把二階段的SMMU頁(yè)表變大,比如1GB,固定分配給某個(gè)虛擬機(jī)。這樣,設(shè)備在進(jìn)行二階段地址映射時(shí),只需少數(shù)幾項(xiàng)TLB表項(xiàng),就可以做到一直命中,極大降低延遲。需要注意的是,一旦把二階映射的物理空間分配給某設(shè)備,就不能再收回并分給其他設(shè)備。不然,多次回收后,就會(huì)出現(xiàn)物理地址離散化,無(wú)法找到連續(xù)的大物理地址了。
SMMU接受的是從主設(shè)備發(fā)過(guò)來(lái)的物理地址,那它是怎么來(lái)區(qū)分虛擬機(jī)呢?靠的是同樣從主設(shè)備發(fā)送過(guò)來(lái)的vmid/streamid。如果主設(shè)備本身并不支持虛擬化,那就需要對(duì)它進(jìn)行時(shí)分復(fù)用,讓軟件來(lái)寫入vmid/streamid。當(dāng)然,這個(gè)軟件必須運(yùn)行在hypervisor或者是secure monitor,不然會(huì)有安全漏洞。具體的做法,是在虛擬機(jī)切換的時(shí)候,hypervisor修改寄存器化的vmid/streamid,提供輸入給SMMU即可
如果主設(shè)備要實(shí)現(xiàn)硬件的方式支持虛擬化
如果主設(shè)備本身不支持虛擬化,并且本身特別復(fù)雜,那還需要定制驅(qū)動(dòng)。以Arm的圖形處理器為例,到目前為止,硬件上還沒有正式支持虛擬化,如果軟件要支持,可能會(huì)有以下幾種方案:
假設(shè)我們用的Hypervisor是Xen,它運(yùn)行于Arm處理器的EL2,虛擬機(jī)運(yùn)行于EL0/1。正常的圖形處理器驅(qū)動(dòng)會(huì)分成用戶空間與核心空間兩部分。要實(shí)現(xiàn)虛擬化,時(shí)分復(fù)用圖形處理器,Xen上本身不可能跑驅(qū)動(dòng),因?yàn)槟壳膀?qū)動(dòng)只支持Linux。所以就只能讓虛擬機(jī)來(lái)跑原先的驅(qū)動(dòng),而沒有辦法在hypervisor上再運(yùn)行一個(gè)驅(qū)動(dòng)來(lái)進(jìn)行訪問(wèn)控制。同時(shí),重映射圖形處理器在CPU上的二階段地址
Arm現(xiàn)有的中斷控制器GIC600
Armv8.1及之后的CPU,都支持一個(gè)叫VHE的機(jī)制
對(duì)于1型虛擬機(jī),比如Xen
前面說(shuō)到,有些廠商認(rèn)為虛擬化還不夠
同樣的
有了同時(shí)支持虛擬化和硬件隔離的圖形處理器,我們的中控芯片構(gòu)架會(huì)有如下改動(dòng):
至此,虛擬化和隔離結(jié)束,開始討論車規(guī)。
目前我們說(shuō)的車規(guī)分兩個(gè),功能安全和電氣標(biāo)準(zhǔn)。前者由ISO26262定義,后者由AEC-Q100定義。
功能安全在芯片上的設(shè)計(jì)原則是要盡可能多的找出芯片上的失效場(chǎng)景并糾正。失效又分為系統(tǒng)和隨機(jī)兩種,前者依靠設(shè)計(jì)時(shí)的流程規(guī)范來(lái)保證,后者依賴于芯片設(shè)計(jì)上采取的種種失效探測(cè)機(jī)制來(lái)保證。我們?cè)谶@主要談后者。
簡(jiǎn)單來(lái)說(shuō),芯片的失效率,是基于單個(gè)晶體管在某個(gè)工藝節(jié)點(diǎn)的失效概率,推導(dǎo)出片上邏輯或者內(nèi)存的失效概率。面積越大,晶體管越多,相應(yīng)的失效率越大。ISO26262把安全等級(jí)做了劃分,常見的有ASIL-B和ASIL-D級(jí)。ASIL-B要求芯片能夠覆蓋90%的單點(diǎn)失效場(chǎng)景,而ASIL-D則是99%。這其實(shí)是個(gè)非常高的要求。一個(gè)晶體管的失效概率雖低,可是通常一個(gè)復(fù)雜芯片是上億個(gè)晶體管組成的,如果不采取任何措施,那任何一點(diǎn)的錯(cuò)誤都可能造成功能失效,失效率很高。
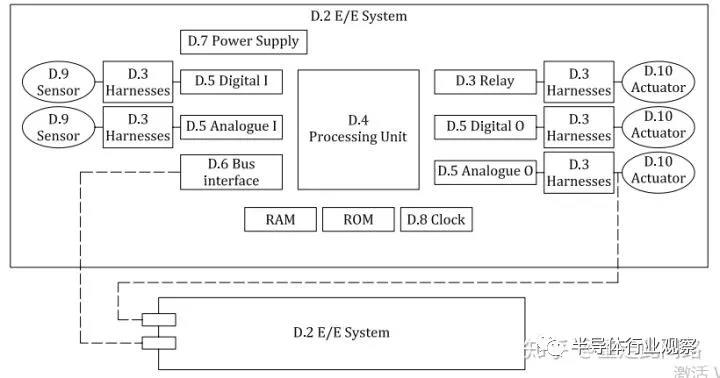
ISO26262手冊(cè)第五篇的附件D,詳細(xì)描述了硬件失效的探測(cè)手段。在這部分,硬件系統(tǒng)被分為幾個(gè)模塊:輸入端有傳感器,連接件,中繼,數(shù)模接口;處理部分包含處理單元,各類內(nèi)存閃存。系統(tǒng)層面有總線,電源和時(shí)鐘。系統(tǒng)框架如下圖:
針對(duì)每一單元,ISO26262手冊(cè)定義了一些方法,來(lái)檢測(cè)這些單元是否失效,并給出每一種方法的可靠度。比如傳輸線,可以有校驗(yàn)碼,超時(shí),計(jì)數(shù)器,發(fā)送測(cè)試向量等。再比如處理單元,可以使用軟硬件自檢,冗余加比較,額外硬件模塊監(jiān)測(cè)等方法。這些方法并不能簡(jiǎn)單的應(yīng)用于芯片功能安全設(shè)計(jì)。那芯片上怎么辦?我們采用自底向上的方法,先從晶體管開始分析,再到IP模塊級(jí),然后到芯片系統(tǒng)級(jí),再討論幾個(gè)典型場(chǎng)景,最后自頂向下分析
在芯片的隨機(jī)錯(cuò)誤中,有一類是永久錯(cuò)誤。這一次,是熱點(diǎn)中的汽車芯片。
,在中國(guó)找不出幾家做前裝汽車芯片的公司。而兩年后的今天,突然如雨后春筍般的涌現(xiàn)出十多家,其范圍涵蓋了輔助駕駛,中控,儀表盤,T-Box,網(wǎng)關(guān),車身控制,電池管理,硬件加解密,激光雷達(dá),毫米波雷達(dá),圖像傳感器和圖像信號(hào)處理器等,八仙過(guò)海各顯神通。
,更不存在絕對(duì)的生態(tài)閉環(huán)。只是量沒有消費(fèi)電子那么大,一年出個(gè)幾百萬(wàn)片就不錯(cuò)了。在這個(gè)領(lǐng)域里,新造車勢(shì)力方興未艾,傳統(tǒng)造車勢(shì)力追求差異化,又趕上5G,自動(dòng)駕駛與人工智能的熱點(diǎn),于是汽車芯片成了繼虛擬現(xiàn)實(shí),礦機(jī),NB-IOT,人工智能之后新的投資方向。
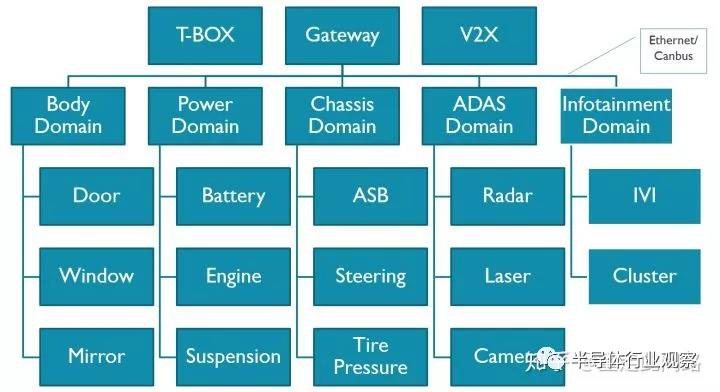
上圖是一個(gè)典型的汽車電子系統(tǒng)框架。這個(gè)系統(tǒng)分為幾個(gè)域,車身,動(dòng)力總成,底盤,信息娛樂(lè),輔助駕駛,網(wǎng)關(guān)和T-Box。每個(gè)域有著各自的域控制器,通過(guò)車載以太網(wǎng)和Can總線互聯(lián)。我們就以架構(gòu)上最復(fù)雜的中控和輔助駕駛芯片為例,展開探討其設(shè)計(jì)思路與方法。
,主要由處理器,圖形處理器,多媒體,圖像處理,安全(Security)管理,功能安全(Safety),片上調(diào)試和總線等子系統(tǒng)構(gòu)成。它和通常的應(yīng)用處理器區(qū)別主要在于虛擬化,功能安全,實(shí)時(shí)性和車規(guī)級(jí)電氣標(biāo)準(zhǔn)。
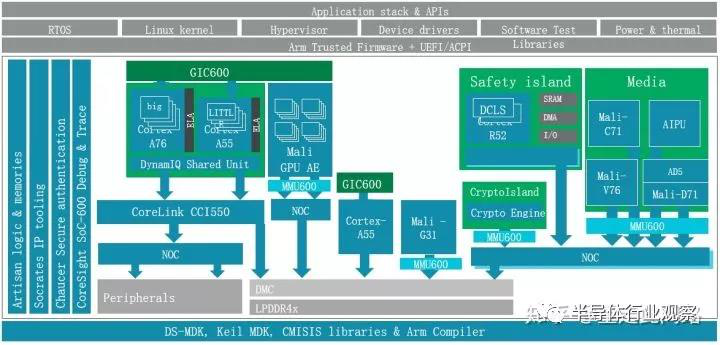
先說(shuō)虛擬化。虛擬化其實(shí)是從服務(wù)器來(lái)的概念,為什么汽車也會(huì)有這個(gè)需求??jī)牲c(diǎn)原因:現(xiàn)在的中控芯片有一個(gè)趨勢(shì),集成儀表盤,降低成本。以前的儀表盤通常是用微控制器做的,圖形界面也較簡(jiǎn)單。而現(xiàn)在的系統(tǒng)越來(lái)越炫,甚至需要圖形處理器來(lái)參與。很自然的,這就使得中控和儀表盤合到單顆芯片內(nèi)。它們跑的是不同的操作系統(tǒng),虛擬化能更好的實(shí)現(xiàn)軟件隔離。當(dāng)然,有些廠商認(rèn)為虛擬化還不夠,需要靠物理隔離才放心,這是后話,稍后展開。另一個(gè)趨勢(shì)是中控本身需要同時(shí)支持多個(gè)屏幕,每個(gè)屏幕分屬于不同的虛擬機(jī)和操作系統(tǒng),這樣能簡(jiǎn)化軟件設(shè)計(jì),提高軟件的可靠性。
。可以依靠處理器自帶的二階內(nèi)存管理單元(s2MMU),實(shí)現(xiàn)軟件虛擬機(jī);也可以在內(nèi)存控制器前放一個(gè)硬件防火墻,對(duì)訪問(wèn)內(nèi)存的地址進(jìn)行檢查和過(guò)濾,不做地址重映射;還可以使用系統(tǒng)內(nèi)存管理單元SMMU實(shí)現(xiàn)完整的硬件虛擬化,這是我們要重點(diǎn)介紹的。
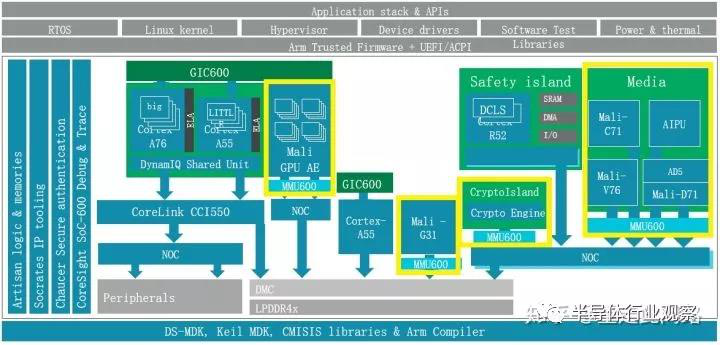
如上圖黃色框所示,每個(gè)主設(shè)備和總線之間,都加了一個(gè)MMU600。為什么每個(gè)主設(shè)備后都要加 ?很簡(jiǎn)單 ,如果不加,那必然存在安全漏洞 ,和軟件虛擬化無(wú)異 。那為何不用防火墻?防火墻的的實(shí)現(xiàn)方法 ,通常是用一個(gè)片上內(nèi)存來(lái)存放過(guò)濾表項(xiàng) 。如果做到4K字節(jié)的顆粒度,那4G字節(jié)內(nèi)存就需要1百萬(wàn)項(xiàng) ,每項(xiàng)8位 ,總共1MB的片上內(nèi)存,這是個(gè)不小的成本 。另外一個(gè)原因是 ,防火墻方案的物理地址空間對(duì)軟件是不透明的,采用系統(tǒng)內(nèi)存管理器SMMU600對(duì)上層軟件透明,更貼近虛擬化的需求。
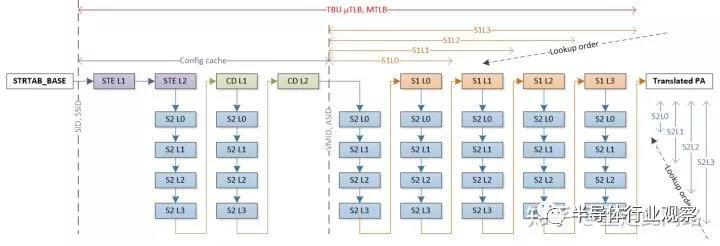
當(dāng)處理器發(fā)起一次地址虛實(shí)轉(zhuǎn)換請(qǐng)求,內(nèi)存管理單元會(huì)在內(nèi)部的TLB緩存和Table Walk緩存查找最終頁(yè)表項(xiàng)和中間表項(xiàng)。如果在內(nèi)部緩存沒找到,那就需要去系統(tǒng)緩存或者內(nèi)存讀取。在最差情況下,每一階的4層中間表可能都是未命中,4x4+4=20,最終會(huì)需要20次內(nèi)存讀取。對(duì)于系統(tǒng)內(nèi)存管理器,情況可能更糟。如上圖所示,由于SMMU本身還需引入多級(jí)描述符來(lái)映射多個(gè)頁(yè)表,最極端情況需要36次的訪存才能找到最終頁(yè)表項(xiàng)。如果所有訪問(wèn)都是這個(gè)延遲,顯然無(wú)法接受。
,主設(shè)備的5萬(wàn)次訪問(wèn),在經(jīng)過(guò)SMMU后,產(chǎn)生了近5萬(wàn)次未命中。這意味著訪問(wèn)的平均延遲等于訪存延遲,150ns以上,效果如下:?梢钥吹?div id="4qifd00" class="flower right">
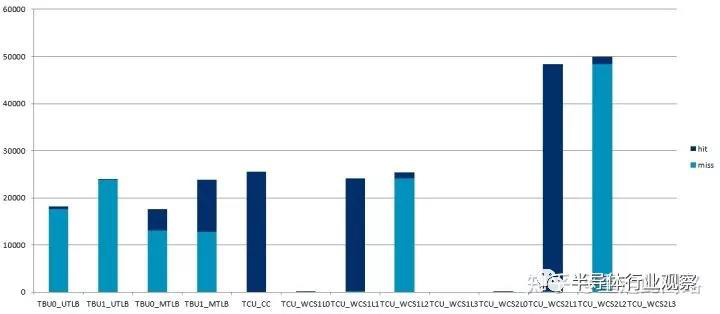
這是啟用2階地址映射后的實(shí)測(cè)結(jié)果,其各項(xiàng)緩存大小均配置成較大,然后把兩個(gè)主設(shè)備連到接口,進(jìn)行地址較為隨機(jī)的訪問(wèn)?div id="4qifd00" class="flower right"> 。另一方面 ,處理器開了虛擬機(jī)后,它的隨機(jī)訪存效率 ,和未開虛擬機(jī)比 ,卻能做到80%以上,這是為什么呢 ?答案很簡(jiǎn)單 ,處理器內(nèi)部的MMU,會(huì)把中間頁(yè)表的物理地址繼續(xù)發(fā)到二級(jí)或者三級(jí)緩存 ,利用緩存來(lái)減少平均延遲 。而SMMU就沒有這么幸運(yùn),在Arm先前的手機(jī)處理器參考設(shè)計(jì)中 ,并沒有系統(tǒng)緩存 。這種情況下,即使對(duì)于延遲不太敏感的主設(shè)備 ,比如圖形處理器 ,打開虛擬化也會(huì)造成性能損失,可能高達(dá)9% ,這不是一個(gè)小數(shù)目 。
,會(huì)引入網(wǎng)狀結(jié)構(gòu)總線 ,而不是之前的crossbar結(jié)構(gòu)的一致性總線。網(wǎng)狀結(jié)構(gòu)總線的好處 ,主要是提升了頻率和帶寬 ,并且,在提供多核一致性的同時(shí),也可以把系統(tǒng)緩存交給各個(gè)主設(shè)備使用。不需要緩存的主設(shè)備還是可以和以前一樣發(fā)出非緩存的的數(shù)據(jù)傳輸,避免額外占用緩存,引起頻繁的緩存替換;同時(shí),SMMU可以把頁(yè)表和中間頁(yè)表項(xiàng)放在緩存,從而縮短延遲。
如果我們讀一下Arm的SMMU3.x協(xié)議,會(huì)發(fā)現(xiàn)它是支持雙向頁(yè)表維護(hù)信息廣播的,這意味著除了緩存數(shù)據(jù)一致性外,所有的主設(shè)備,只要遵循SMMU3.x協(xié)議,可以和處理器同時(shí)使用一張頁(yè)表。在輔助駕駛芯片設(shè)計(jì)時(shí),如果需要,把重要的加速器加入同一張頁(yè)表,可以避免軟件頁(yè)表更新操作,進(jìn)一步提高異構(gòu)計(jì)算的效率。不過(guò)就SMU600而言 ,它僅僅支持單向的廣播 ,接了SMU600的主設(shè)備,本身的緩存和頁(yè)表操作并不能廣播到處理器 ,反過(guò)來(lái)是可以的 。
。如果訪問(wèn)時(shí)的id和預(yù)設(shè)的不符,SMMU會(huì)報(bào)異常給hypervisor。
,那本身需要根據(jù)多組寄存器設(shè)置,主動(dòng)發(fā)出不同的vmid/streamid。為了對(duì)軟件兼容,可以把不同組按照4KB邊界分開,這樣在二階地址映射時(shí),可以讓相同的實(shí)地址訪問(wèn)不同組的寄存器,而對(duì)驅(qū)動(dòng)透明。同時(shí),對(duì)于內(nèi)部的資源也要做區(qū)分,不能讓數(shù)據(jù)互相影響。如果用到緩存,那緩存還必須對(duì)vmid敏感,相同地址不同vmid的情況,必須識(shí)別為未命中。
,讓寄存器訪問(wèn)和數(shù)據(jù)通路處于‘穿透’的模式,不引起異常,提高效率。相應(yīng)的,讓虛擬機(jī)直接訪問(wèn)寄存器,那訪問(wèn)控制就實(shí)現(xiàn)不了了。為了實(shí)現(xiàn)多虛擬機(jī)的調(diào)度,我們可以在hypervisor里面實(shí)現(xiàn)一個(gè)調(diào)度器,并且在核心態(tài)的驅(qū)動(dòng)部分開放接口,讓hypervisor可以主動(dòng)調(diào)度。示意圖如下:
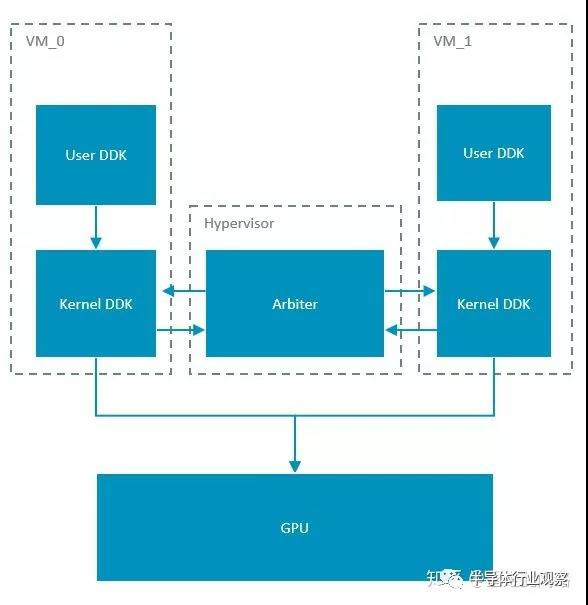
這個(gè)實(shí)現(xiàn)的優(yōu)點(diǎn)很明顯,改動(dòng)較少,實(shí)現(xiàn)簡(jiǎn)單,無(wú)論是Xen和KVM都可以適配。缺點(diǎn)是主動(dòng)權(quán)并不掌握在hypervisor,如果某個(gè)虛擬機(jī)上渲染任務(wù)過(guò)于繁重,一直不把控制權(quán)交給調(diào)度器,那只有強(qiáng)制重啟。另一個(gè)明顯的缺點(diǎn)是,無(wú)法在圖形處理器同時(shí)運(yùn)行兩個(gè)虛擬機(jī)上的任務(wù)。這就需要另一種虛擬機(jī)的實(shí)現(xiàn)方式,如下圖:
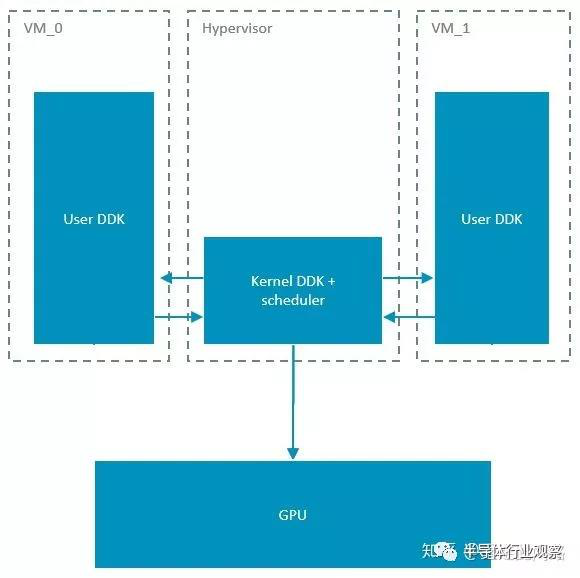
在這種實(shí)現(xiàn)下,虛擬機(jī)里只跑驅(qū)動(dòng)的用戶空間,所有涉及核心空間的調(diào)用全都扔到Hypervisor。這要求hypervisor本身是Linux,只有KVM符合這個(gè)要求。Arm的Mali圖形處理器,硬件上是支持指定某個(gè)渲染核心跑特定任務(wù)的,也就是可以把某個(gè)虛擬機(jī)的任務(wù)運(yùn)行在特定渲染核心的。這樣,如果有實(shí)時(shí)性的操縱系統(tǒng)要跑,比如儀表盤,可以保留出一個(gè)核來(lái),不被其他虛擬機(jī)搶占,來(lái)實(shí)現(xiàn)一定程度的QoS。此時(shí),圖形處理器是真正同時(shí)跑兩個(gè)虛擬機(jī)任務(wù)的,而不是時(shí)分復(fù)用。至于輸出的frame buffer,不同的任務(wù)是可以放到不同物理地址的,只是沒法區(qū)分SteamID,沒法做隔離。
Arm支持硬件虛擬化的圖形處理器估計(jì)還要一年才會(huì)出來(lái)
。具體到細(xì)節(jié),虛擬化除了需要寄存器分組,緩存對(duì)vmid敏感之外,通用的一些單元也需要支持分組。
關(guān)于虛擬機(jī)的效率,還有兩點(diǎn)需要注意:
,受限于GICv3.x協(xié)議,是沒有辦法繞過(guò)hypervisor,直接把虛擬中斷送到Guest OS的。外部中斷送進(jìn)來(lái),還是得經(jīng)由hypervisor權(quán)限設(shè)置寄存器,產(chǎn)生一個(gè)虛擬中斷到Guest OS。中斷直接送到Guest OS要到GICv4才會(huì)改進(jìn)。
,可以加速2型虛擬機(jī)的切換。具體原理是,KVM等2型虛擬機(jī),Hypervisor就在Linux核心里面,而Linux需要完整的2階3/4層頁(yè)表。另外一方面,Armv8.1之前的處理器EL2沒有對(duì)應(yīng)的頁(yè)表。如果沒有VHE,那這個(gè)Hypervisor必須把一部分駐留在EL2做高權(quán)限操作,而Host Linux還是運(yùn)行在EL1。這樣,很多操作需要從EL1陷入EL2,改完再回到EL1的Linux核心,多了一層跳轉(zhuǎn) 。有了VHE ,那么Host Linux核心直接運(yùn)行在EL2,可以操作EL1的4層頁(yè)表的頁(yè)表寄存器 ,軟件上不用做修改 。硬件上,這些訪問(wèn)會(huì)被重定向到EL2 ,以保證權(quán)限 。
,這個(gè)改動(dòng)沒有影響 。這里我們要提一下QNX的虛擬機(jī),它是1型虛擬機(jī) 。QNX是目前唯一一個(gè)能達(dá)到Asil-D等級(jí)的操作系統(tǒng)(包含Hypervisor) 。如果需要實(shí)現(xiàn)Asil-D級(jí)別的系統(tǒng),必須把現(xiàn)有的軟件從Linux系統(tǒng)移植到QNX 。所幸的是 ,QNX也是符合Posix標(biāo)準(zhǔn)的,尤其是圖形處理器的驅(qū)動(dòng),移植起來(lái)會(huì)省事一些 。QNX不是所有的模塊都是Asil-D級(jí) ,移植過(guò)去的驅(qū)動(dòng),其實(shí)是沒有安全等級(jí)的。QNX依靠Asil-D級(jí)的核心軟件模塊和Hypervisor,保證99%以上的失效覆蓋率。如果子模塊出了問(wèn)題,那只能重啟子模塊。
,有些場(chǎng)景要物理隔離。虛擬化的時(shí)候,硬件資源還是共享的,只不過(guò)對(duì)軟件是透明。這樣其實(shí)并不能完全防止硬件的沖突和保證優(yōu)先級(jí)。請(qǐng)注意,硬件隔離是separation,而不是分區(qū)partition,Partition是用MPU來(lái)做的。在中控的系統(tǒng)框架圖內(nèi),我們把采用物理隔離的紅色部分單獨(dú)列出來(lái),如下圖:
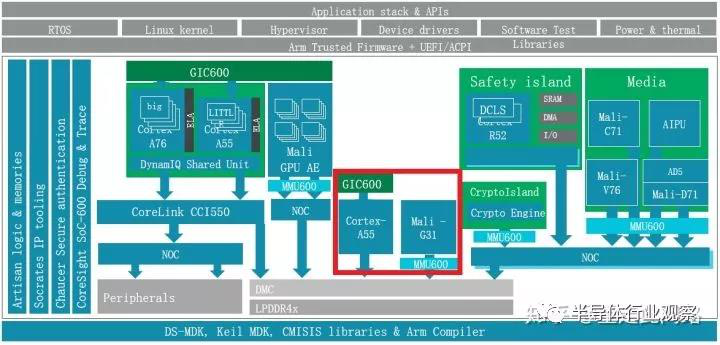
此時(shí)的處理器A55和圖形處理器G31,獨(dú)立于作為信息娛樂(lè)域的處理器A76/A55和圖形處理器G76之外,擁有自己的電源,時(shí)鐘和電壓。作為優(yōu)化,紅色部分可以和其余的處理器用一致性總線連接起來(lái),在不作為儀表盤應(yīng)用的時(shí)候,作為SMP的一部分來(lái)使用。而需要隔離的時(shí)候,用多路選擇連接到NoC或者內(nèi)存控制器 。這樣既節(jié)省了面積 ,又實(shí)現(xiàn)了隔離。
,圖形處理器也有物理隔離的需求 。實(shí)現(xiàn)其實(shí)并不復(fù)雜,比支持硬件虛擬化要直接 ,如下圖:
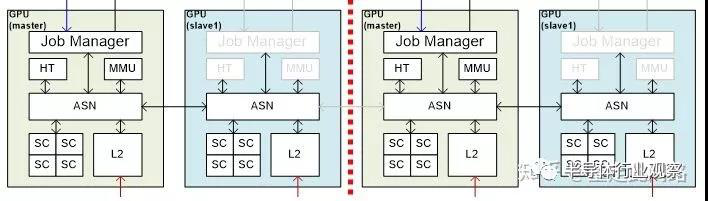
由于圖形處理器面積最大的是渲染核心SC ,這部分不動(dòng) 。其余的硬件模塊,每組核都復(fù)制一份 ,組和組之間用內(nèi)部總線ASN互聯(lián) 。當(dāng)拆成多個(gè)圖形處理器的時(shí)候,每個(gè)冗余模塊分別控制自己的資源 。此時(shí) ,每組GPU需要獨(dú)立運(yùn)行一個(gè)驅(qū)動(dòng)。而把所有資源融合運(yùn)行的時(shí)候 ,冗余的部分自動(dòng)關(guān)閉 ,由一個(gè)模塊集中調(diào)度。此時(shí) ,某些公用資源可能會(huì)遇到性能瓶頸 ,但汽車通常只會(huì)要求物理隔離兩個(gè)組,分別給儀表盤和信息娛樂(lè),并且儀表盤所需資源較少,融合的時(shí)候,可以啟用信息娛樂(lè)的共享單元,從而避免瓶頸。對(duì)于系統(tǒng)中其余的主設(shè)備,也可以利用類似的設(shè)計(jì)思路來(lái)實(shí)現(xiàn)隔離。
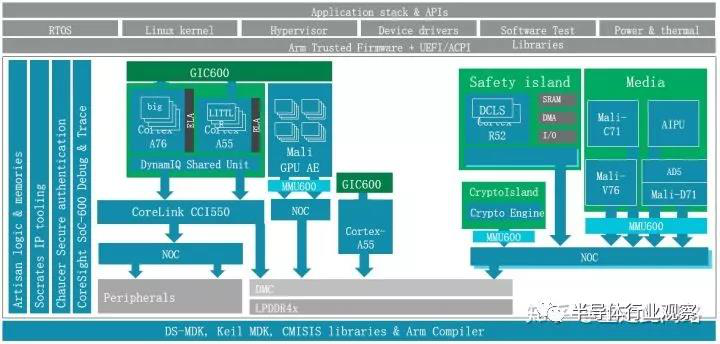
此時(shí)圖形處理器的物理隔離和硬件虛擬化可以同時(shí)啟用,跑多份驅(qū)動(dòng),滿足前文的需求。
 。
。